There are plenty of articles in zhihu, wechat official accounts and github on how to scraper from web. Scrapy, one of the most powerful open source python package , is almost capable for all web-scraping job. Here, I note the basic steps in scraping with looter and the data visualisation on crawled data with pyecharts.
Basic scraping steps
The basic steps in scraping are: first send a request, and followed by parsing the response and ended by data storage.
Make a Requests
One can send a request in using the package requests
>>> import requests
>>> r = requests.get('https://api.github.com/events') # return a Response object r
>>> r.text # return the content of the response
>>> r.status_code # check the response status
While with looter one can
looter shell <your url>
>>> import looter as lt
# in looter, has from lxml import etree
# lxml is used for processing XML and HTML, Elements are list and carry attributes as a dict
>>> tree = lt.fetch(url) # return etree.HTML(r.text), the ElementTree of the response
Parse a Response
To parse a ElementTree, one can use cssselect and xpath, here I’ll use cssselect. For the response requested directly by requests.get, we first convert the content of the response explicitly with lxml.etree, while for looter, a tree object has already been returned by fetch.
# with looter, we don't need import it explicitly, as it has already importted within it.
>>> from lxml import etree
>>> tree = etree.HTML(r.text)
# select the interesting part of tree with CSS tag
>>> items = tree.cssselect('td input') # select the input class inside table td, td and input are html/css tag
>>> items = tree.cssselect('.question-summary') #another example for stackoverflow
# cssselect usually return a list of Element
>>> items
[<Element div at 0x1037f89c8>, <Element div at 0x1037f8a08>, ..., <Element div at 0x103954ac8>]
>>> item = items[0]
>>> item
<Element div at 0x1037f89c8>
# item may contains a dict
>>> item.attrib # Elements carry attributes as a dict
{'class': 'question-summary', 'id': 'question-summary-231767'}
>>> subitem = item.cssselect('a.question-hyperlink')
>>> len(subitem) # a list
1
>>> subitem[0].attrib
{'href': '/questions/231767/what-does-the-yield-keyword-do', 'class': 'question-hyperlink'}
>>> subitem[0].text
'What does the “yield” keyword do?'
Save wanted data
For data, we can write with json; for image, here we use directly the function in looter. One can has its own realization in reference that in looter.
>>> import looter as lt # use function in looter
>>> save_img(item.attrib.get("data-src")) # dict with key 'data-src' has a url link value
Scraping with looter
As declared in its documentation, if one want to quickly write a spider, you can use looter to automaticaly generate one :)
looter genspider <name> <tmpl> [--async]
In this code, tmpl is template, inculdes data and image. async is an option which represents generating a spider using asyncio instead of threadpool. In the generated template, you can custom the domain, and the tasklist. tasklist is actually the pages you want to crawl.
domain = 'https://konachan.com'
tasklist = [f'{domain}/post?page={i}' for i in range(1, 9777)]
And then you should custom your crawl function, which is the core of your spider.
def crawl(url):
tree = lt.fetch(url)
items = tree.cssselect('ul li')
for item in items:
data = dict()
# data[...] = item.cssselect(...)
pprint(data)
In most cases, the contents you want to crawl is a list (ul or ol tag in HTML), you can select them as items. Then, just use a for loop to iterate them, and select the things you want, storing them to a dict. But before you finish this spider, you’d better debug your cssselect codes using shell provided by looter.
Here is a example within looter (with small modifications, write data to json, instead print it on screen)
import looter as lt
from pprint import pprint
from concurrent import futures
domain = 'https://stackoverflow.com'
total = []
def crawl(url):
tree = lt.fetch(url)
items = tree.cssselect('.question-summary')
for item in items:
data = dict()
data['question'] = item.cssselect('a.question-hyperlink')[0].text
data['link'] = domain + item.cssselect('a.question-hyperlink')[0].get('href')
data['votes'] = int(item.cssselect('.vote-count-post strong')[0].text)
data['answers'] = int(item.cssselect('.status strong')[0].text)
data['views'] = int(''.join(item.cssselect('.views')[0].get('title')[:-6].split(',')))
data['timestamp'] = item.cssselect('.relativetime')[0].get('title')
data['tags'] = []
listTags = item.cssselect('a.post-tag')
for tag in listTags:
data['tags'].append(tag.text)
#data['tags'] = item.cssselect('a.post-tag')[1].text
#pprint(data)
lt.save_as_json(total, name='stackoverflow')
total.append(data)
if __name__ == '__main__':
tasklist = [f'{domain}/questions/tagged/python?page={n}&sort=votes&pagesize=50' for n in range(1, 31)]
#result = [crawl(task) for task in tasklist]
with futures.ThreadPoolExecutor(10) as executor:
executor.map(crawl, tasklist)
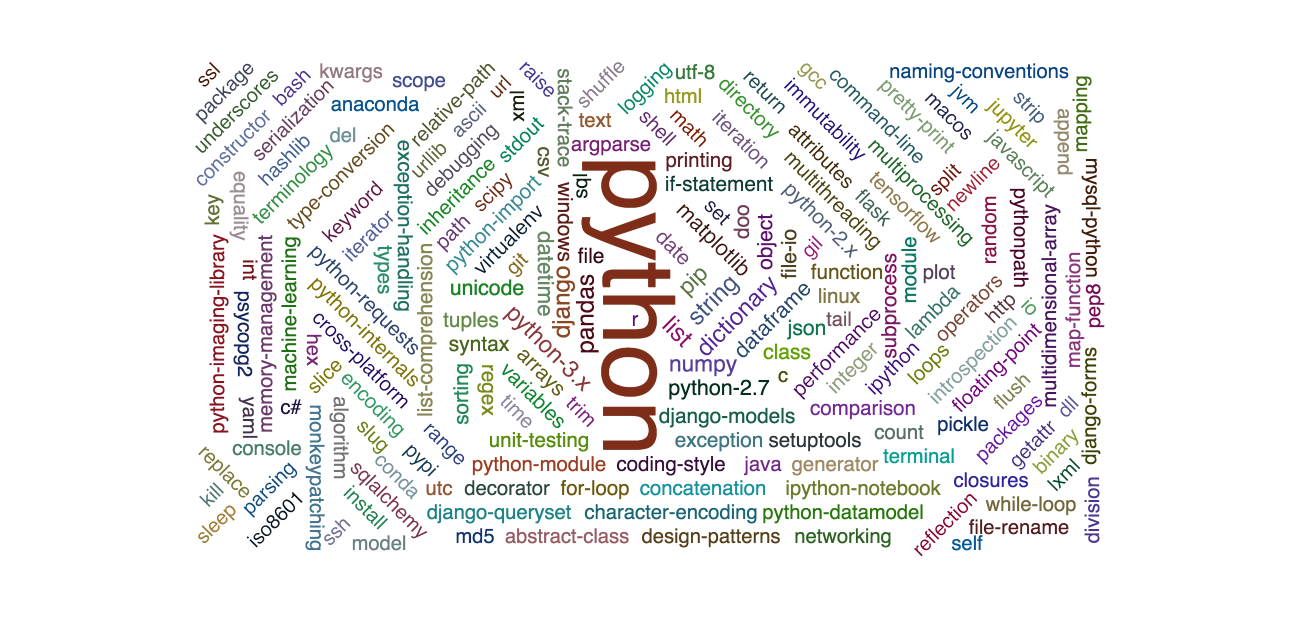
Data Visualisation
Here I just show one possibility, using pyecharts. To use pyecharts, it seems we need to convert the crawled data in two lists, one stored the data and the other store its frequency. Here is a example
import json
from pprint import pprint
from pyecharts import WordCloud
tag = []
with open('stackoverflow.json') as json_file:
data = json.load(json_file)
for tgs in data:
for t in tgs['tags']:
tag.append(t)
tagNm = []
tagNb = []
for t in tag:
if t in tagNm:
tagNb[tagNm.index(t)] = tagNb[tagNm.index(t)]+1
else:
tagNm.append(t)
tagNb.append(1)
wordcloud = WordCloud(width=1300, height=620)
wordcloud.add("", tagNm, tagNb, word_size_range=[20, 100])
wordcloud.render()
and its results